728x90
1. LogisticRegression
sklearn.linear_model
사이킷런의 ML 알고리즘 모듈 안의 로지스틱 회귀를 사용할 때 모델 최적화를 위해 부여할 수 있는 옵션들이 있다.
max_iter는 기본 100으로 설정되어 있는데,
간혹 반복 횟수가 적다는 경고(ConvergenceWarning: lbfgs failed to converge (status=1))가 뜰 때
solver(최적화에 사용할 알고리즘. default='lbfgs')가 충분히 수렴할 수 있도록 반복 횟수를 늘려주면 된다.
보통 작은 데이터 세트의 이진 분류인 경우 liblinear가 성능이 좋고, 데이터 세트가 크고 다중 분류인 경우 lbfgs가 적합하다.
2. 결정 트리 모델의 시각화
Graphviz 패키지 사용!
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz
iris_data = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size = 0.2, random_state = 11)
# Version 1
dt_clf = DecisionTreeClassifier(random_state=11)
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
export_graphviz(dt_clf, out_file = "tree.dot", class_names = iris_data.target_names, \
feature_names = iris_data.feature_names, impurity = True, filled = True)
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
# Version 2: tree2.dot: max_depth = 3. 트리의 깊이가 3이 되면 노드 분할을 멈춤
dt_clf = DecisionTreeClassifier(max_depth = 3, random_state=156)# 학습 수행
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
export_graphviz(dt_clf, out_file = "tree2.dot", class_names = iris_data.target_names, \
feature_names = iris_data.feature_names, impurity = True, filled = True) # impurity = True는 지니계수 출력, filled = True는 클래스를 색으로 분류
with open("tree2.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
# Version 3: min_samples_split = 4. 샘플 데이터 수가 4보다 작으면 노드 분할을 멈춤
dt_clf = DecisionTreeClassifier(min_samples_split = 4, random_state=156)# 학습 수행
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
export_graphviz(dt_clf, out_file = "tree3.dot", class_names = iris_data.target_names, \
feature_names = iris_data.feature_names, impurity = True, filled = True) # impurity = True는 지니계수 출력, filled = True는 클래스를 색으로 분류
with open("tree3.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
# Version 4: min_samples_leaf이 4로 분할된 좌/우 브랜치 노드에 샘플 데이터 수가 4가 남으면 노드 분할을 멈춤
dt_clf = DecisionTreeClassifier(min_samples_leaf = 4, random_state=156)# 학습 수행
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
export_graphviz(dt_clf, out_file = "tree4.dot", class_names = iris_data.target_names, \
feature_names = iris_data.feature_names, impurity = True, filled = True) # impurity = True는 지니계수 출력, filled = True는 클래스를 색으로 분류
with open("tree4.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
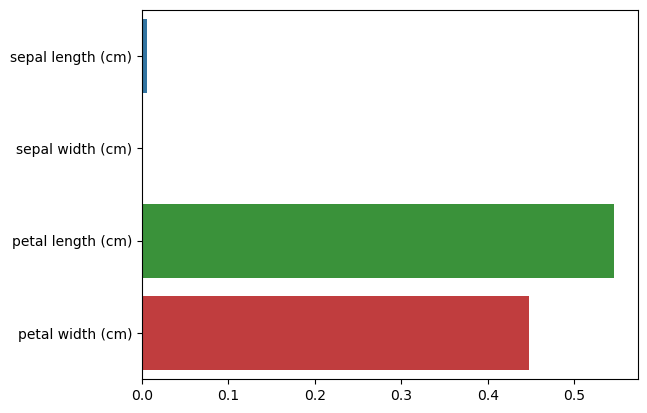
# Iris 데이터셋의 피처별 중요도 추출
import matplotlib
import seaborn as sns
import numpy as np
%matplotlib inline
print("Feature importances: \n{0}".format(np.round(dt_clf.feature_importances_, 3)))
for name, value in zip(iris_data.feature_names, dt_clf.feature_importances_):
print('{0}: {1:.3f}'.format(name, value))
sns_plot = sns.barplot(x = dt_clf.feature_importances_, y = iris_data.feature_names)
fig = sns_plot.get_figure()
fig.savefig("feature_importances.png")



728x90
'SeSAC 금융데이터 분석가 > 머신러닝' 카테고리의 다른 글
| 10/17 월 (0) | 2022.10.28 |
|---|---|
| 10/14 금 (0) | 2022.10.14 |
| 10/11 화 (0) | 2022.10.11 |

