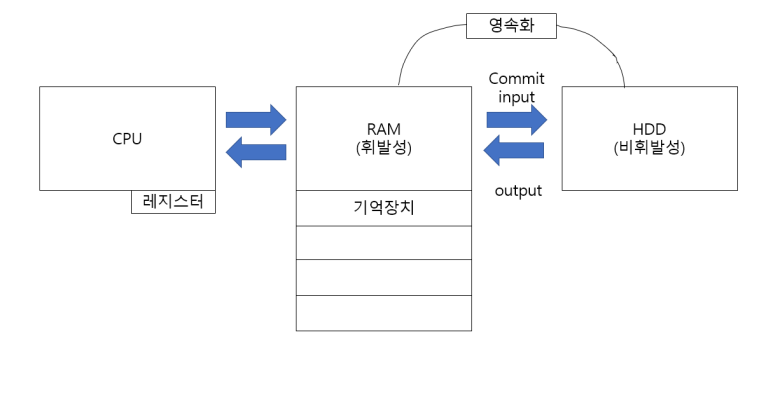
1. DB I/O 및 저장 구조
- input: RAM에서 HDD로 접근해서 데이터 값을 입력
- output: HDD에서 RAM으로 데이터를 출력
- 랜덤 액세스: 다른 데이터를 설명해주는 데이터가 있을 때 CPU가 RAM에서 메타데이터(변수)를 이용하여 주소 값을 알아낸 후 RAM이나 HDD로 바로 데이터를 불러오는 방식
- 시퀀셜 액세스: 논리적(인덱스 리프 블록)또는 물리적으로 연결된 순서에 따라 차례대로 블록을 읽는 방식
* 테이블의 경우 서로 논리적인 연결 고리를 가지고 있지 않음, 세그먼트에 할당된 익스텐트 목록을 헤더에 맵(각 익스텐트의 첫 번째 블록 주소 값을 가짐)으로 관리함, 맵에서 목록을 얻고 각 익스텐트의 첫 번째 블록부터 순서대로 읽는 것이 Full Table Scan
- 풀 스캔: 메타데이터가 없는 상태에서 데이터를 찾아야 하는 경우, RAM/HDD 등 메모리에서 처음부터 끝까지 돌면서 찾는 과정
- 데이터 파일: 디스크 상의 물리적인 OS 파일
- 테이블 스페이스: 세그먼트를 담는 컨테이너, 여러 개의 데이터 파일로 구성됨
- 세그먼트: 데이터 저장 공간이 필요한 오브젝트(테이블, 인덱스, 파티션, LOB 등), 여러 개의 익스텐트로 구성됨, 테이블/인덱스를 생성할 때 데이터를 어떤 테이블 스페이스에 저장할지 지정함(각각 하나의 세그먼트), 파티션일 경우 각 파티션이 하나의 세그먼트
- 익스텐트: 공간을 확장하는 단위, 연결된 블록들의 집합, 테이블/인덱스의 공간이 부족해지면 해당 오브젝트가 속한 테이블 스페이스로부터 익스텐트를 추가로 할당 받음
- 블록: DBMS가 데이터를 읽고 쓰는 단위(데이터 I/O 단위)
- LOB: Large OBject, 구조화되지 않은 용량이 큰 데이터를 저장할 수 있는 데이터 타입

- DB 버퍼 캐시: 데이터 캐시, 디스크에서 읽은 데이터 블록을 캐싱해 둠으로써 같은 블록에 대한 반복적인 I/O Call을 줄이는데 목적이 있음. 데이터 블록을 읽을 땐 항상 버퍼 캐시부터 탐색함
- 논리적 I/O: SQL을 수행하면서 읽은 총 블록 I/O. SQL문을 처리하는 과정에서 메모리 버퍼 캐시에서 발생한 총 블록 I/O을 말함
- 물리적 I/O: SQL 처리 도중 읽어야 할 블록을 버퍼 캐시에서 찾지 못할 때만 디스크에 액세스 하므로, 논리적 블록 I/O 중 일부를 물리적으로 I/O함. 디스크에서 발생한 총 블록 I/O을 말함
* 디스크 I/O가 메모리 I/O보다 10000배쯤 느림
- BCHR(Buffer Cache Hit Ratio, 버퍼 캐시 히트율): 읽은 전체 블록 중에서 물리적인 디스크 I/O를 수반하지 않고 곧바로 메모리에서 찾는 비율
BCHR = ( 캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수 ) x 100
= ( (논리적 I/O - 물리적 I/O) / 논리적 I/O ) x 100
= ( 1 - (물리적 I/O) / (논리적 I/O) ) x 100
* SQL 성능을 높이기(SQL 튜닝) 위해서 할 수 있는 일은 논리적 I/O(더불어 물리적 I/O도 줌)를 줄이는 일, BCHR이 높다고 해서 무조건 효율적인 SQL을 의미하지 않음(같은 블록을 비효율적으로 반복해서 읽는 경우)
- Single Block I/O: 한 번에 한 블록씩 요청해서 메모리에 적재하는 방법. 테이블/인덱스 블록 모두 기본적으로 이 방식을 사용
- Multi Block I/O: 한 번에 여러 블록씩 요청해서 메모리에 적재하는 방법. 인덱스를 이용하지 않고 테이블 전체를 스캔할 때 사용
- Table Range Scan: 인덱스를 이용하여 큰 테이블에서 소량의 데이터를 검색
- Table Full Scan: 읽을 데이터가 일정량을 넘으면 데이블 전체를 스캔하는 것이 유리
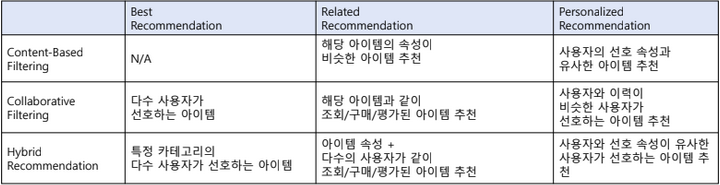
2. 추천 시스템 분류
- 요건
Best: Popularity가 높은 아이템 추천
Related: 주어진 아이템과 유사도가 높은 아이템(대체제/보완제) 추천
Personalized: 사용자(혹은 사용자와 유사한 사용자들)의 선호도가 높은 아이템 추천

- 데이터
Explicit Feedback: 사용자의 아이템에 대한 명시적 선호 정보를 가진 이력 Ex) Rating
Implicit Feedback: 사용자의 아이템에 대한 암시적 선호 정보를 가진 이력 Ex) 사용자의 아이템 소비 이력
- 모델
CBF, CF, Hybrid
- 계량 방식
Rating, Prediction, Top-K Rec
'SeSAC 금융데이터 분석가 > 추천시스템' 카테고리의 다른 글
| 11/29 화 (0) | 2022.11.29 |
|---|
