수요일!
어제~오늘까지 Numpy! 오늘 오후~이번 주까지 Pandas 진도!
Anaconda Prompt에서 Jupyter notebook 실행
conda activate machine
jupyter notebook
1. 행렬곱 연산은 앞쪽의 2차원 matrix 열과 뒤쪽의 2차원 matrix 행 개수가 같아야 함. (3, 2) * (2, 2)
import numpy as np
arr1 = np.array([[1,2,3], [4,5,6]]) # (2,3)
arr2 = np.array([[4,5],[6,7],[8,9]]) # (3,2)
print(np.matmul(arr1, arr2)) # matmul() 함수 사용해서 계산. 결과는 (2,2)
# [[ 40 46]
# [ 94 109]]
2. 전치행렬(transpose)은 행은 열로, 열은 행으로 바꿔줌
arr = np.array([[1,2,3], [4,5,6]]) #(2,3)
print(arr)
print(arr.T) # T라는 속성을 사용. (3,2)
# [[1 2 3]
# [4 5 6]]
# [[1 4]
# [2 5]
# [3 6]]
3. iterator(반복자)를 이용한 반복문 처리. ndarray는 python의 for문과 달리 while문과 iterator를 이용
1차원. flags=['c_index']은 1차원. .index 메서드 사용
arr = np.array([1,2,3,4,5]) # (5,)
# for tmp in arr: # python의 for문
# print(tmp)
my_iter = np.nditer(arr, flags=['c_index']) # iterator 객체를 얻어옮. 변수 넣고 flags라는 속성으로 차원 정해줌
# print(my_iter) # <numpy.nditer object at 0x0000019C75B253F0> 인덱스 값 출력
while not my_iter.finished: # my_iter의 iterator가 가르치는 값이 끝이 아니면 계속 반복(True)
idx = my_iter.index
print(arr[idx]) # index의 요소 출력
my_iter.iternext() # iterator 다음으로 이동
# 1
# 2
# 3
# 4
# 52차원. flags=['multi_index']은 다차원. .multi_index 메서드 사용
for문이 여럿 쓰여야 하는 것에 비해, 몇 차원인지 알 필요 없고 while문 한 번만 돌면 됨
arr = np.array([[1,2,3],[4,5,6]]) # (2,3)
# for tmp1 in range(arr.shape[0]): # 행에 대한 range. range(2). 2차원이니까 for문 2번
# for tmp2 in range(arr.shape[1]): # 열에 대한 range. range(3)
# print(arr[tmp1, tmp2])
my_iter = np.nditer(arr, flags=['multi_index']) # flags 속성은 다차원
while not my_iter.finished:
idx = my_iter.multi_index # 다차원에서는 multi_index 메서드 사용
# print(idx)
print(arr[idx], idx)
my_iter.iternext()
# 1 (0, 0)
# 2 (0, 1)
# 3 (0, 2)
# 4 (1, 0)
# 5 (1, 1)
# 6 (1, 2)
4. 집계 함수. Numpy가 제공하는 sum() 함수와 ndarray가 가진 메서드로 모든 요소를 더함
arr = np.arange(1,7,1).reshape(2,3) # reshape로 원본 ndarray의 view를 2행 3열로 만듦
print(arr) # [[1 2 3]
# [4 5 6]]
print(np.sum(arr)) # 21. 모든 요소의 합. Numpy가 제공하는 함수
print(arr.sum()) # 21. ndarray가 가진 메서드
print(arr.mean()) # 3.5. 평균
print(arr.max()) # 6. 최대값
print(arr.min()) # 1. 최소값
print(arr.argmax()) # 5. 가장 큰 값의 인덱스
print(arr.std()) # 1.707825127659933. 표준편차
5. axis(축) 개념. 0부터 시작하는 축을 숫자로 표현. ndarray는 축을 지정해주지 않으면 전체에 대해 연산함. 다차원에서는 axis가 바뀜.
1차원은 열 방향 axis=0
2차원은 열 방향 axis=1, 행 방향 axis=0
3차원은 면 방향 axis=0, 행 방향 axis=1, 열 방향 axis=2
arr = np.arange(1,7,1).reshape(2,3)
print(arr) # [[1 2 3]
# [4 5 6]]
print(arr.sum(axis=0)) # [5 7 9]. 행 방향 axis를 부여해서 열끼리 합을 구함
print(arr.sum(axis=1)) # [ 6 15]. 열 방향 axis를 부여해서 행끼리 합을 구함
6. 연습문제. Boolean indexing을 사용해 ndarray 안에 10보다 큰 수가 몇 개인지 구하기
arr = np.arange(1, 17, 1).reshape(4,4)
print(arr)
my_mask = (arr > 10)
# print(arr[my_mask])
print(len(arr[my_mask]))
print(my_mask.sum())
print((arr > 10)) # Boolean indexing
print((arr > 10).sum()) # True = 1. True를 모두 더해라!
- Numpy 수업 끝! -
- Pandas 수업 시작! -
ndarray의 정렬, 연결, 삭제, CSV 파일 로딩은 Numpy가 아닌 Pandas로 처리. Pandas의 Alias는 관용적으로 pd
Numpy가 ndaray라는 데이터 타입을 제공하듯이, Pandas도 Series, DataFrame이라는 데이터 타입을 제공함
Series : 1차원 자료구조. 같은 데이터 타입만 저장 가능
DataFrame : 2차원 자료구조. Series의 집합
Anaconda Prompt에서 Pandas 설치
conda activate machine
conda install pandas
import numpy as np
import pandas as pd
arr = np.array([1,2,3,4,5], dtype=np.float64)
print(arr)
s = pd.Series([1,2,3,4,5], dtype=np.float64) # Series. 내부적으로 사용하는 데이터 타입은 ndarray의 것
print(s) # 앞은 인덱스(key), 뒤는 요소(value)
print(s.values) # [1. 2. 3. 4. 5.]. 요소만 출력하라. Numpy array(ndarray)
print(s.index) # RangeIndex(start=0, stop=5, step=1). 인덱스만 출력하라. Pandas의 객체
print(s.dtype) # float64
# [1. 2. 3. 4. 5.]
# 0 1.0
# 1 2.0
# 2 3.0
# 3 4.0
# 4 5.0
# dtype: float64
# [1. 2. 3. 4. 5.]
# RangeIndex(start=0, stop=5, step=1)
# float64
1. Series의 indexing. 인덱스를 숫자가 아닌 내가 임의로 줄 수 있음(dict의 key와 같이)
s = pd.Series([1,2,3,4,5],
dtype=np.float64, # 실수가 기본 데이터 타입.
index=['c', 'b', 'a','kk', '홍길동']) # 인덱스를 문자로 지정해주기. 기존의 숫자 인덱스는 숨어있음
print(s)
# c 1.0
# b 2.0
# a 3.0
# kk 4.0
# 홍길동 5.0
# dtype: float64
print(s[0], s['c']) # 1.0 1.0. 숫자/지정 인덱스
# print(s[100], s['haha']) # Error!인덱스를 숫자로 지정해주기
s = pd.Series([1,2,3,4,5],
dtype=np.float64,
index=[0, 2, 100, 6, 9]) # 인덱스를 숫자로 지정해주기
print(s)
# 0 1.0
# 2 2.0
# 100 3.0
# 6 4.0
# 9 5.0
print(s[0]) # 1.0
# print(s[1]) # Error! 지정 인덱스가 숫자이면 기존의 숫자 인덱스를 쓸 수 없음. Error!
print(s[100]) # 3.0지정 인덱스에 중복 값이 있어도 사용 가능. 모두 Series로 들고옮. 가능하지만 지양
s = pd.Series([1,2,3,4,5],
dtype=np.float64,
index=['c', 'b', 'c', 'k', 'm']) # 지정 인덱스에 중복값이 있음
print(s)
# c 1.0
# b 2.0
# c 3.0
# k 4.0
# m 5.0
# dtype: float64
print(s['c']) # 인덱스가 'c'인 것을 모두 Series로 가져옴
# c 1.0
# c 3.0
# dtype: float64
2. Series의 slicing. 지정 인덱싱은 start/stop 모두 포함(숫자 인덱싱은 포함/불포함)
s = pd.Series([1,2,3,4,5],
dtype=np.float64,
index=['c', 'b', 'a', 'k', 'm'])
print(s[0:3])
print(s['c':'a']) # 지정 인덱싱은 start/stop 모두 포함(숫자 인덱싱은 포함/불포함)
# c 1.0
# b 2.0
# a 3.0
# dtype: float64
3. Series의 Boolean indexing과 Fancy indexging
s = pd.Series([1,2,3,4,5],
dtype=np.float64,
index=['c', 'b', 'a', 'k', 'm'])
print(s)
print(s[s % 2 == 0]) # Boolean indexing. Mask 만들어서 짝수인 요소들 인덱싱
print(s[[0,2]]) # Fancy indexing
# b 2.0
# k 4.0
# dtype: float64
# c 1.0
# a 3.0
# dtype: float64
4. Series를 만드는 또 다른 방법. dictionary로 index를 key, 저장하는 값을 value로 넣기
my_dict = {'서울': 1000,
'인천': 500,
'제주': 200}
s = pd.Series(my_dict)
print(s)
# 서울 1000
# 인천 500
# 제주 200
# dtype: int64
5. list comprehension : list 생성 시 제어문(for, if)을 이용
연습문제 1
# 연습문제. A 공장의 2020년 1월 1일부터 10일간의 생산량을 Series로 저장
# 생산량은 평균이 50이고 표준편차가 5인 정규분포에서 랜덤하게 생성(정수)
# index가 날짜
import numpy as np
import pandas as pd
from datetime import datetime, timedelta
start_day = datetime(2020,1,1) # 날짜 객체
# print(start_day) # 2020-01-01 00:00:00
# my_list = [tmp for tmp in range(100)] # list comprehension : list 생성 시 제어문(for, if)을 이용
# print(my_list)
# my_list = [tmp for tmp in range(100) if tmp % 2 == 0] # 0~99 사이의 짝수만 list로 출력
# print(my_list)
my_list = [int(x) for x in np.random.normal(50,5,(10,))]
s = pd.Series(my_list,
index=[start_day + timedelta(days=x) for x in range(10)]) # start_day timedelta(날짜 차이, 1일)를 더해줌
print(s) # 2020년 1월 1일부터 10일 간의 생산량을 랜덤하게 출력
연습문제 2
# 연습문제. A 공장의 2020년 1월 1일부터 10일간의 생산량을 Series로 저장
# 생산량은 평균이 50이고 표준편차가 5인 정규분포에서 랜덤하게 생성(정수)
# index가 날짜
# 연습문제. B 공장의 2020년 1월 1일부터 10일간의 생산량을 Series로 저장
# 생산량은 평균이 70이고 표준편차가 8인 정규분포에서 랜덤하게 생성(정수)
# index가 날짜
import numpy as np
import pandas as pd
from datetime import datetime, timedelta
start_day = datetime(2020,1,1)
s1 = pd.Series([int(x) for x in np.random.normal(50,5,(10,))],
index=[start_day + timedelta(days=x) for x in range(10)])
print(s1)
s2 = pd.Series([int(x) for x in np.random.normal(70,8,(10,))],
index=[start_day + timedelta(days=x) for x in range(10)])
print(s2)
print(s1 + s2)2020-01-01 47
2020-01-02 46
2020-01-03 46
2020-01-04 46
2020-01-05 52
2020-01-06 56
2020-01-07 54
2020-01-08 45
2020-01-09 42
2020-01-10 48
dtype: int64
2020-01-01 72
2020-01-02 70
2020-01-03 68
2020-01-04 65
2020-01-05 61
2020-01-06 62
2020-01-07 57
2020-01-08 66
2020-01-09 75
2020-01-10 61
dtype: int64
2020-01-01 119
2020-01-02 116
2020-01-03 114
2020-01-04 111
2020-01-05 113
2020-01-06 118
2020-01-07 111
2020-01-08 111
2020-01-09 117
2020-01-10 109
dtype: int64연습문제 3
# 연습문제. A 공장의 2020년 1월 1일부터 10일간의 생산량을 Series로 저장
# 생산량은 평균이 50이고 표준편차가 5인 정규분포에서 랜덤하게 생성(정수)
# index가 날짜
# 연습문제. B 공장의 2020년 1월 5일부터 10일간의 생산량을 Series로 저장
# 생산량은 평균이 70이고 표준편차가 8인 정규분포에서 랜덤하게 생성(정수)
# index가 날짜
import numpy as np
import pandas as pd
from datetime import datetime, timedelta
start_day_A_factory = datetime(2020,1,1)
start_day_B_factory = datetime(2020,1,5)
my_list = [int(x) for x in np.random.normal(50,5,(10,))]
s1 = pd.Series([int(x) for x in np.random.normal(50,5,(10,))],
index=[start_day_A_factory + timedelta(days=x) for x in range(10)])
print(s1)
s2 = pd.Series([int(x) for x in np.random.normal(70,8,(10,))],
index=[start_day_B_factory + timedelta(days=x) for x in range(10)])
print(s2)
print(s1 + s2) # Series는 인덱스가 똑같은 것끼리 연산함. A orB 공장에는 있는 인덱스, B or A 에는 없다면 NaN2020-01-01 42
2020-01-02 52
2020-01-03 54
2020-01-04 53
2020-01-05 42
2020-01-06 55
2020-01-07 42
2020-01-08 47
2020-01-09 48
2020-01-10 56
dtype: int64
2020-01-05 78
2020-01-06 58
2020-01-07 56
2020-01-08 64
2020-01-09 61
2020-01-10 84
2020-01-11 59
2020-01-12 84
2020-01-13 75
2020-01-14 69
dtype: int64
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 NaN
2020-01-04 NaN
2020-01-05 120.0
2020-01-06 113.0
2020-01-07 98.0
2020-01-08 111.0
2020-01-09 109.0
2020-01-10 140.0
2020-01-11 NaN
2020-01-12 NaN
2020-01-13 NaN
2020-01-14 NaN
dtype: float64
6. Pandas의 DataFrame. 2차원 matrix 구조. Series의 집합. dictionary를 이용해서 만듦
my_dict = {'이름': ['홍길동', '아이유', '김연아', '신사임당'],
'학년': [4, 3, 1, 2],
'학점': [1.5, 2.4, 3.9, 3.2]}
df = pd.DataFrame(my_dict)
# print(df) # 보기 불편함
display(df) # DataFrame을 DB table처럼 출력
# 이름 학년 학점
# 0 홍길동 4 1.5
# 1 아이유 3 2.4
# 2 김연아 1 3.9
# 3 신사임당 2 3.2
print(df.shape) # (4, 3). 2차원 4행 3열
print(df.values) # 값들로만 구성된 ndarray 출력
print(df.size, df.ndim) # 12 2. DataFrame 안에 있는 요소들의 갯수, 차원
print(df.index) # RangeIndex(start=0, stop=4, step=1). 행 index
print(df.columns) # Index(['이름', '학년', '학점'], dtype='object'). 컬럼으로만 구성된 ndarray 출력. 열 index
df.index.name = '학번' # 행 index에 대한 이름을 지정
df.columns.name = '학생정보' # 열 index에 대한 이름을 지정
display(df)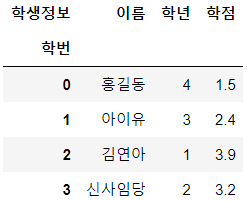
7. DataFrame의 column 명과 index 명을 변경. rename()
my_dict = {'이름': ['홍길동', '아이유', '김연아', '신사임당'],
'학년': [4, 3, 1, 2],
'학점': [1.5, 2.4, 3.9, 3.2]}
df = pd.DataFrame(my_dict)
display(df)
new_df = df.rename(columns={'이름':'학생이름',
'학점':'평균평점'},
index={0:'one'},
inplace=False) # inplace가 True이면 원본을 수정, False면 사본을 만듦
display(new_df)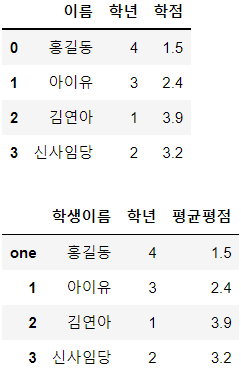
8. DataFrame의 특정 column을 index(행)로 설정. set_index()
my_dict = {'이름': ['홍길동', '아이유', '김연아', '신사임당'],
'학년': [4, 3, 1, 2],
'학점': [1.5, 2.4, 3.9, 3.2]}
df = pd.DataFrame(my_dict)
display(df)
new_df = df.set_index('이름',
inplace=False)
display(new_df)
9. 여러 가지 resource(CSV, MySQL DB, Open API, JSON)를 이용해서 DataFrame을 생성
sample data(student.csv)를 C:\jupyter_home\data 경로에 넣고 끌어오기
df = pd.read_csv('./data/student.csv')
display(df)
| 1. 3/15 화 | 2. 3/16 수 | 3. 3/17 목 | 4. 3/18 금 | 5. 3/21 월 |
| ML 환경 설정 (아나콘다, 주피터 노트북), Pandas, Numpy, ndarray |
ML Numpy, 행렬곱연산, 전치행렬, iterator, axis, Pandas, Series, DataFrame |
ML Pandas |
ML Pandas |
ML |
* 행렬곱 연산, iterator, axis, Series, DataFrame의 개념을 확실히 집고 넘어가자!



