목요일!
오늘도 Multinomial Classification를 대표적인 예제(MNIST)를 통해 배운다~
손으로 쓴 숫자들로 이루어진 대형 데이터베이스~
MNIST 이미지는 그 자체가 2차원이고 그런 게 여럿이기 때문에 3차원. 이미지를 1차원으로 ravel() 해야 함
https://www.kaggle.com/competitions/digit-recognizer/data?select=test.csv
Digit Recognizer | Kaggle
www.kaggle.com
Tensorflow Ver. 1.15은 배운 이론을 코드로 이해하기에는 좋지만 코드가 너무 어렵다.
1. Multinomial Classification by Tensorflow Ver. 1.15 - MNIST
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# Raw Data Loading
df = pd.read_csv('./data/mnist/train.csv')
# display(df.shape) # (42000, 785)
# display(df.head())
# 데이터 전처리 : 결측치나 이상치 없음. 단, 정규화는 필요함
# 이미지 확인
figure = plt.figure()
ax_arr = [] # python list
img_data = df.drop('label', axis=1, inplace=False).values
for n in range(10):
ax_arr.append(figure.add_subplot(2,5,n+1))
ax_arr[n].imshow(img_data[n].reshape(28,28), # 28 x 28 픽셀로 변환
cmap='Greys', # cmap은 흑백 이미지 처리
interpolation='nearest') # interpolation는 보간법(이미지 깨지지 않도록)
plt.tight_layout()
plt.show()
# Data Split
train_x_data, test_x_data, train_t_data, test_t_data = \
train_test_split(df.drop('label', axis=1, inplace=False), df['label'], test_size=0.3, random_state=1, stratify=df['label'])
# 정규화
scaler = MinMaxScaler()
scaler.fit(train_x_data)
norm_train_x_data = scaler.transform(train_x_data)
norm_test_x_data = scaler.transform(test_x_data)
import warnings
warnings.filterwarnings('ignore')
# Tensorflow Implementation
sess = tf.Session()
onehot_train_t_data = sess.run(tf.one_hot(train_t_data, depth=10)) # class가 0 ~ 9까지 총 10개
onehot_test_t_data = sess.run(tf.one_hot(test_t_data, depth=10))
# Placeholder
X = tf.placeholder(shape=[None,784], dtype=tf.float32) # 독립변수(feature)의 개수
T = tf.placeholder(shape=[None,10], dtype=tf.float32) # class의 logistic 개수
# Weight, bias
W = tf.Variable(tf.random.normal([784,10])) # 독립변수 784개, 종속변수 10개. W는 7840개
b = tf.Variable(tf.random.normal([10])) # = logistic 개수
# Model, Hypothesis
logit = tf.matmul(X,W) + b
H = tf.nn.softmax(logit)
# Cross Entropy(loss func)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logit, labels=T))
# Train
train = tf.train.GradientDescentOptimizer(learning_rate=1e-1).minimize(loss)
# Session 초기화
sess.run(tf.global_variables_initializer())
# 반복 학습
num_of_epoch = 1000
batch_size = 100
for step in range(num_of_epoch):
total_batch = int(norm_train_x_data.shape[0] / batch_size) # 학습 데이터의 개수 / batch
for i in range(total_batch):
batch_x = norm_train_x_data[i*batch_size:(i+1)*batch_size] # [0:100], [100:200] ~. 100개씩 Slicing
batch_y = onehot_train_t_data[i*batch_size:(i+1)*batch_size]
_, loss_val = sess.run([train, loss], feed_dict={X:batch_x, T:batch_y})
if step % 100 == 0:
print('loss val : {}'.format(loss_val))# 성능평가(Accuracy)
predict = tf.argmax(H,1)
correct = tf.equal(predict, tf.argmax(T,1))
accuracy = tf.reduce_mean(tf.cast(correct, dtype=tf.float32))
accuracy_val = sess.run(accuracy, feed_dict={X:norm_test_x_data, T:onehot_test_t_data})
print('Accuracy : {}'.format(accuracy_val)) # 0.9070634841918945

새로운 가상환경에 필요한 Libraries 설치~
conda create -n machine_TF2 python=3.8 openssl
conda activate machine_TF2
conda install numpy pandas matplotlib nb_conda tensorflow
pip install sklearn
jupyter notebook
1.15 버전에서 W의 값을 알아내려면 session을 통해서 node를 실행시켜 값을 얻어야 했음
2.x 버전은 eager execution(즉시 실행 모드)을 지원하기 때문에 session 초기화 코드와 placeholder가 불필요하고 일반적인 프로그래밍처럼 사용할 수 있음
Keras가 Tensorflow 2.x 안에 포함되어 있고 tf.keras 형태로 사용할 수 있음. 가장 중요한 개념은 Model
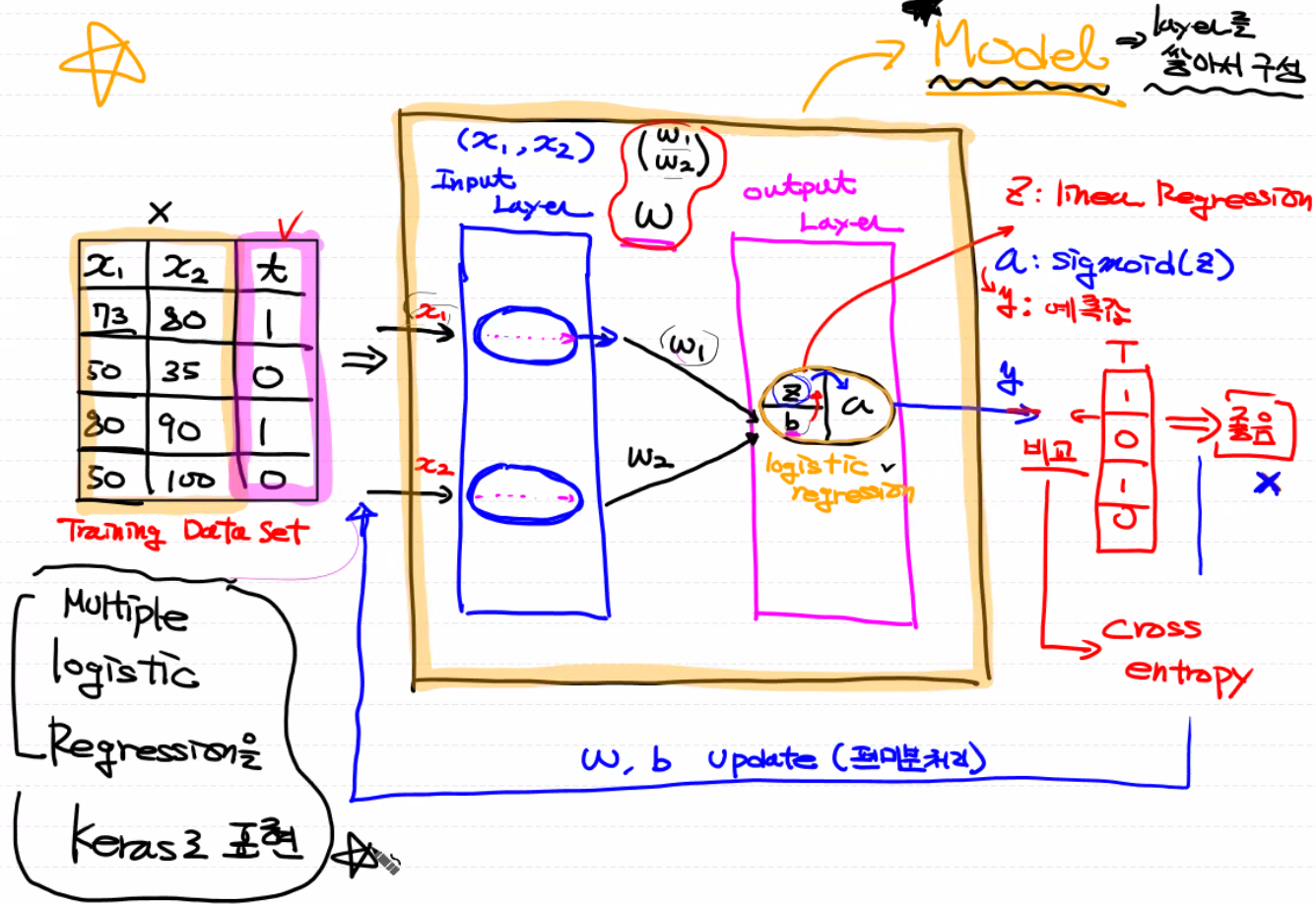
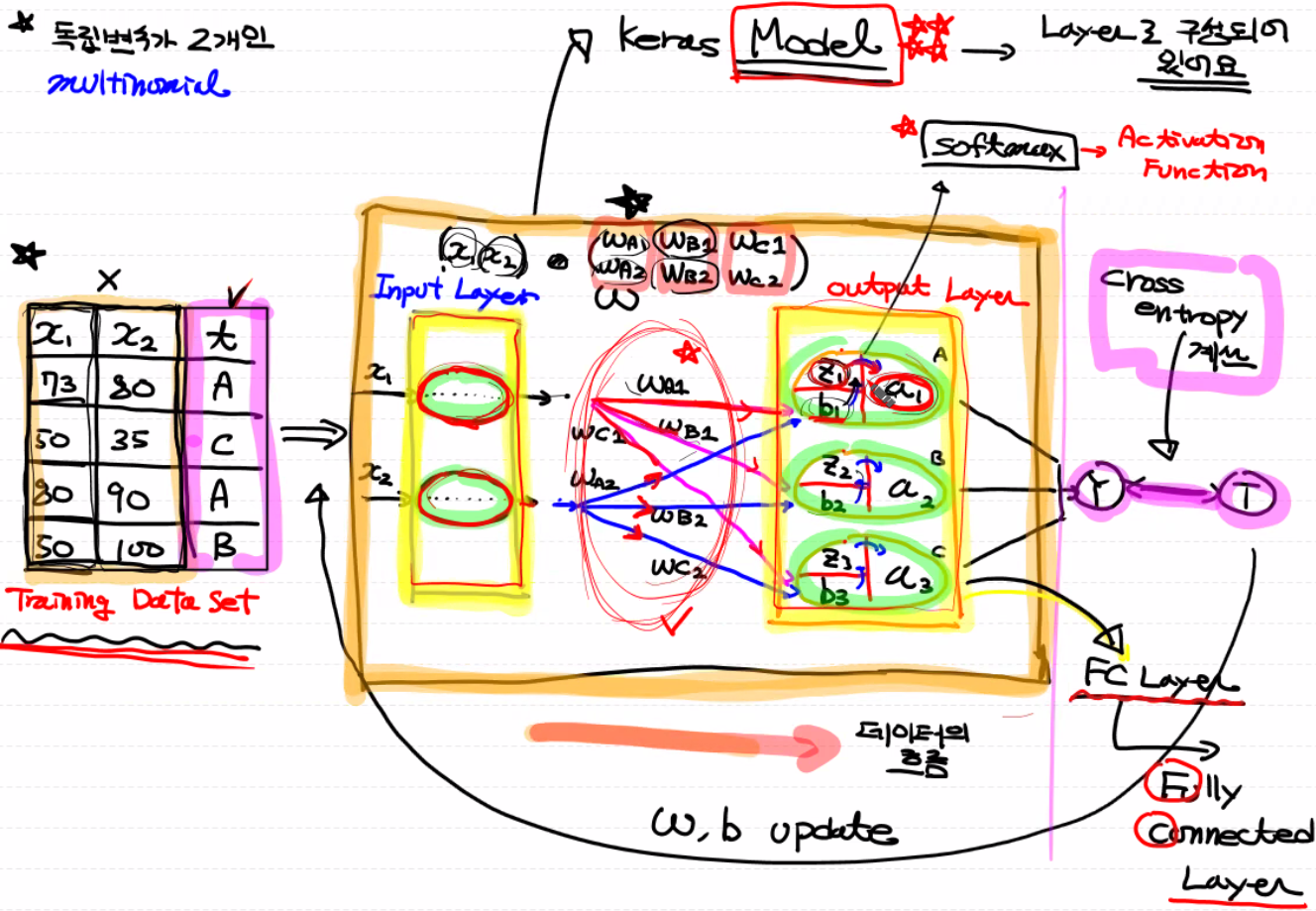
# Keras의 model 만들기의 순서
import tensorflow as tf
# model = tf.keras.models.Sequential()
# model.add('input layer') # layer 추가
# model.add('output layer')
# model.compile() # loss의 종류와 optimizer 종류를 설정
# model.fit() # 학습(마치 Sklearn 사용하는 것처럼)
# model.evaluate() # 평가와 predict
# model.predict()
# model.save() # model 저장
2. Multinomial Classification by Tensorflow Ver. 2.0 - MNIST
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense # Flatten는 input layer, Dense는 output layer용
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# Raw Data Loading
df = pd.read_csv('./data/mnist/train.csv')
# Data Split
train_x_data, test_x_data, train_t_data, test_t_data = \
train_test_split(df.drop('label', axis=1, inplace=False),
df['label'],
test_size=0.3,
random_state=1,
stratify=df['label'])
# 정규화
scaler = MinMaxScaler()
scaler.fit(train_x_data)
norm_train_x_data = scaler.transform(train_x_data)
norm_test_x_data = scaler.transform(test_x_data)
# Tensorflow 2.x 구현
# model 생성
model = Sequential()
# layer 추가
model.add(Flatten(input_shape=(norm_train_x_data.shape[1],))) # input layer. 튜플로 입력
model.add(Dense(units=10, activation='softmax')) # output layer. class와 logistic의 개수는 10
# print(model.summary()) # 구해야 할 W의 개수(7850)를 알려줌
# model compile : 사용할 loss 함수를 지정, 사용할 optimizer(알고리즘)를 지정
from tensorflow.keras.optimizers import SGD
# loss
# linear regression : mse(linear)
# binary classification : binary_crossentropy
# multinomial classification : categorical_crossentropy
model.compile(optimizer=SGD(learning_rate=1e-3),
loss='sparse_categorical_crossentropy', # sparse로 원핫인코딩 처리까지
metrics=['accuracy'])
# 학습 결과를 변수에 저장
history = model.fit(norm_train_x_data, train_t_data,
epochs=100, batch_size=100,
verbose=1, validation_split=0.2) # val_accuracy가 높아야!
# 최종 평가
# print(model.evaluate(norm_test_x_data, test_t_data)) # accuracy: 0.8767
위에 만든 모델을 저장해놓아야 프로그램을 종료해도 메모리에 저장돼 있는 모델이 날아가지 않음
모델 재학습과 공유가 가능!
모델 저장 시 구조와 계산된 W, b를 같이 저장할 수 있음 → 편하지만 사이즈가 크다 : h5(HDF5) 형식
모델 저장 시 구조는 제외하고 W, b만 저장 → 크기가 작지만 사용하려면 먼저 모델을 만들고 W, b 로딩 : checkpoint
3. 모델 저장
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense # Flatten는 input layer, Dense는 output layer용
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.callbacks import ModelCheckpoint
import warnings
warnings.filterwarnings('ignore')
# Raw Data Loading
df = pd.read_csv('./data/mnist/train.csv')
# 기존에는 test_x_data, test_t_data 이 두 데이터를 validation 용도로 사용함. 이제는 test 용도로 사용할 것
# Keras는 학습할 때 train data를 일정 부분 나누어 자체 평가가 가능
# Data Split
train_x_data, test_x_data, train_t_data, test_t_data = \
train_test_split(df.drop('label', axis=1, inplace=False),
df['label'],
test_size=0.3,
random_state=1,
stratify=df['label'])
# 정규화
scaler = MinMaxScaler()
scaler.fit(train_x_data)
norm_train_x_data = scaler.transform(train_x_data)
norm_test_x_data = scaler.transform(test_x_data)
# loss 함수를 sparse_categorical_crossentropy로 지정할 것이기 때문에 label에 대한 one-hot endoding 처리가 필요 없음
# model 생성
model = Sequential()
# layer 추가
model.add(Flatten(input_shape=(norm_train_x_data.shape[1],))) # input layer. 튜플로 입력
model.add(Dense(units=10, activation='softmax'))
model.compile(optimizer=SGD(learning_rate=1e-3),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# model 저장. 구조 빼고 checkpoint 이용해 W, b만 저장. 어디에 저장할지 알려줌
checkpoint_path = './training_ckpt/cp.ckpt'
cp_callback = ModelCheckpoint(filepath=checkpoint_path, save_weights_only=True, verbose=1)
# 학습 결과를 변수에 저장
history = model.fit(norm_train_x_data, train_t_data,
epochs=100, batch_size=100,
verbose=1, validation_split=0.2, # verbose=0이면 출력 안됨
callbacks=[cp_callback]) # 학습할 때마다 W를 저장하라
# 최종 평가
print(model.evaluate(norm_test_x_data, test_t_data)) # loss: 0.4814 - accuracy: 0.8759
4. 모델 불러오기 : 학습하지 않고 평가 vs. 모델 재설정 후 평가
# 1. 학습하지 않은 상태로 evaluation 진행 -> 좋지 않은 결과
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense # Flatten는 input layer, Dense는 output layer용
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.callbacks import ModelCheckpoint
import warnings
warnings.filterwarnings('ignore')
# Raw Data Loading
df = pd.read_csv('./data/mnist/train.csv')
# 기존에는 test_x_data, test_t_data 이 두 데이터를 validation 용도로 사용함. 이제는 test 용도로 사용할 것
# Keras는 학습할 때 train data를 일정 부분 나누어 자체 평가가 가능
# Data Split
train_x_data, test_x_data, train_t_data, test_t_data = \
train_test_split(df.drop('label', axis=1, inplace=False),
df['label'],
test_size=0.3,
random_state=1,
stratify=df['label'])
# 정규화
scaler = MinMaxScaler()
scaler.fit(train_x_data)
norm_train_x_data = scaler.transform(train_x_data)
norm_test_x_data = scaler.transform(test_x_data)
# loss를 sparse_categorical_crossentropy로 지정할 것이기 때문에 one-hot endoding 처리가 필요 없음
# model 생성
model = Sequential()
# layer 추가
model.add(Flatten(input_shape=(norm_train_x_data.shape[1],))) # input layer. 튜플로 입력
model.add(Dense(units=10, activation='softmax'))
model.compile(optimizer=SGD(learning_rate=1e-3),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 학습 없이 최종 평가
print(model.evaluate(norm_test_x_data, test_t_data)) # accuracy: 0.0706. 정확도 7%
# 2. checkpoint에 있는 W를 load한 후 model을 재설정하고 평가 -> 좋은 결과
checkpoint_path = './training_ckpt/cp.ckpt'
model.load_weights(checkpoint_path)
print(model.evaluate(norm_test_x_data, test_t_data)) # accuracy: 0.8759. 정확도 87%
| 1. 3/15 화 | 2. 3/16 수 | 3. 3/17 목 | 4. 3/18 금 | 5. 3/21 월 |
| ML 환경 설정 (아나콘다, 주피터 노트북), Pandas, Numpy, ndarray |
ML Numpy, 행렬곱연산, 전치행렬, iterator, axis, Pandas, Series, DataFrame |
ML Pandas, DataFrame, 함수들 |
ML Pandas, 데이터 분석, 데이터 전처리 |
ML Pandas, 데이터 전처리, 수행평가 |
| 6. 3/22 화 | 7. 3/23 수 | 8. 3/24 목 | 9. 3/25 금 | 10. 3/28 월 |
| ML 데이터 시각화, Matplotlib, 기술통계 |
ML 기술통계 |
ML 기술통계, 머신러닝 |
ML 미분, Regression |
ML 머신러닝 기법들, Regression |
| 11. 3/29 화 | 12. 3/30 수 | 13. 3/31 목 | 14. 4/1 금 | 15. 4/4 월 |
| ML Regression 구현 (Python, Scikit-Learn) |
ML Outlier, Z-score, MinMaxScaler, 다변수 |
ML Tensorflow, Classification |
ML Binary Classification, Logistic Regression |
ML 평가지표(Metrics) |
| 16. 4/5 화 | 17. 4/6 수 | 18. 4/7 목 | 19. 4/8 금 | 20. 4/11 월 |
| ML 평가 시 주의사항 (Over-fitting, Regularization, Over-Sampling) |
ML Multinomial Classification, SGD Classifier, Softmax, batch |
ML Multinomial Classification Tensorflow 2.0 Keras |
ML |
Deep Learning |
* 새로운 개념들 머리에 넣기!



