목요일!
오늘은 우리가 주력으로 사용할 Tensorflow를 배운다! 🐱🏍
수행평가 또 나왔넹..
데이터 핸들링 2 + 머신러닝(다중선형회귀) 1. 4/5 화요일까지 제출!!
Ozone 데이터로 다중선형회귀를 3가지 방법(Python, Sklearn, Tensorflow)으로 구현, 예측치가 비슷하게 나와야 한다!
당연히 데이터 전처리(결치값, 이상치, 정규화)도~
가장 많이 쓰이는 딥러닝 오픈소스 라이브러리는 Google의 Tensorflow와 Facebook의 PyTorch~
Sklearn은 데이터 양과 변수가 많아지면 속도가 굉장히 느려지기 때문에, Tensorflow를 이용한다.
Tensorflow 2.0 ver.이 등장하면서 이전 버전과는 완전히 다르게 바뀌었다.
기존에 만들었던 가상환경(machine)에는 Tensorflow 1.15 ver.을, 새로운 가상환경에는 2 ver.을 설치한다.
conda install tensorflow==1.15하지만!! 사용 중인 Python은 3.8 ver.이기 때문에, Tensorflow 1.15 ver.과 호환이 안 된다..
(Dependency 때문에 Python 3.6~3.7 ver. 필요)
어쩔 수 없이 새로운 가상환경을 만들자
conda deactivate
conda create -n machine_TF15 python=3.7 openssl
conda activate machine_TF15
conda install numpy
conda install pandas
conda install matplotlib
pip install sklearn
conda install nb_conda # Jupyter Notebook
conda install tensorflow==1.15
1. data flow graph : Node(수치계산, 데이터의 입출력)와 Edge(Tensor가 지나가는 통로)로 구성된 방향성 있는 graph
Tensor는 다차원 배열

import tensorflow as tf # 1.15 ver.
node1 = tf.constant(10, dtype=tf.float32) # 상수 node를 만들자
node2 = tf.constant(30, dtype=tf.float32)
node3 = node1 + node2
sess = tf.Session() # 그래프를 실행시켜주는 Session이 필요하다
print(sess.run(node1)) # 10.0. graph를 실행시킴
print(sess.run(node3)) # 40.0
print(sess.run([node1, node3])) # [10.0, 40.0]
#------------------------------------------------------------------------------------
# 만약 다차원 데이터가 입력되려면 shape을 지정해야함. 나중에 입력 받을 값을 실수로 사용하겠다
# node1 = tf.placeholder(shape=[2,2], dtype=tf.float32)
node1 = tf.placeholder(dtype=tf.float32) # scalar
node2 = tf.placeholder(dtype=tf.float32)
node3 = node1 + node2
sess = tf.Session()
result = sess.run(node3, feed_dict={node1: 10, node2: 30}) # 입력이 없는 상태에서 sess을 실행하면 오류. feed로 초기값을 지정해줌
print(result) # 40.0
2. Exam 예제에 Tensorflow를 사용해서 다중선형회귀를 구현해보자

# Q1, Q2, Q3, Exam 예제에 Tensorflow를 사용해서 다중선형회귀를 구현해보자
import numpy as np
import pandas as pd
import tensorflow as tf
# Raw Data Loading
df = pd.read_csv('./data/student_exam_score.csv')
# display(df.head())
# Training Data Set
x_data = df.drop('exam', axis=1, inplace=False) # (25, 3)
t_data = df['exam'].values.reshape(-1,1) # (25, 1)
# 학습종료 후 예측
# predict_data = np.array([[90, 100, 95]]) # (1, 3)
# Placeholder
X = tf.placeholder(shape=[None, 3], dtype=tf.float32) # Shape는 입력값이 어떻든 상관없지만, 열은 3개다
T = tf.placeholder(shape=[None, 1], dtype=tf.float32) # Shape는 입력값이 어떻든 상관없지만, 열은 1개다
# Weight, bias. 파이썬의 변수처럼 텐서플로에도 변수처럼 작동하는 Node를 쓰자
W = tf.Variable(tf.random.normal([3,1])) # Shape는 (3, 1). 표준 정규분포에서 난수를 추출
b = tf.Variable(tf.random.normal([1]))
# model(hypothesis, 가설) y = Wx + b
H = tf.matmul(X,W) + b
# loss function. Error(오차, t-y)를 가지고 동작하는 Node
loss = tf.reduce_mean(tf.square(H - T)) # square과 reduce_mean으로 오차의 제곱의 평균(MSE) 구하자
# train node를 생성하자. 경사하강법과 learning rate와 최소 MSE. loss를 가지고 동작하는 Node
train = tf.train.GradientDescentOptimizer(learning_rate=1e-7).minimize(loss)
# Session을 생성하고 초기화를 진행
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 그래프를 실행하기 전에 초기화 구문이 선행되어야 함
# 반복 학습
for step in range(300000):
_, W_val, b_val, loss_val = sess.run([train, W, b, loss], feed_dict={X: x_data, T: t_data})
if step % 30000 == 0:
print('W : {}, b: {}, loss : {}'.format(W_val, b_val, loss_val))
# 학습종료 후 예측
result = sess.run(H, feed_dict={X: np.array([[89, 100, 95]])})
print(result) # 30만번 : [[187.72133]], [[195.62724]], [[191.56349]] / 40만번 : [[194.6791]]
3. 수행평가 : Ozone 데이터로 다중선형회귀를 3가지 방법(Python, Sklearn, Tensorflow)으로 구현
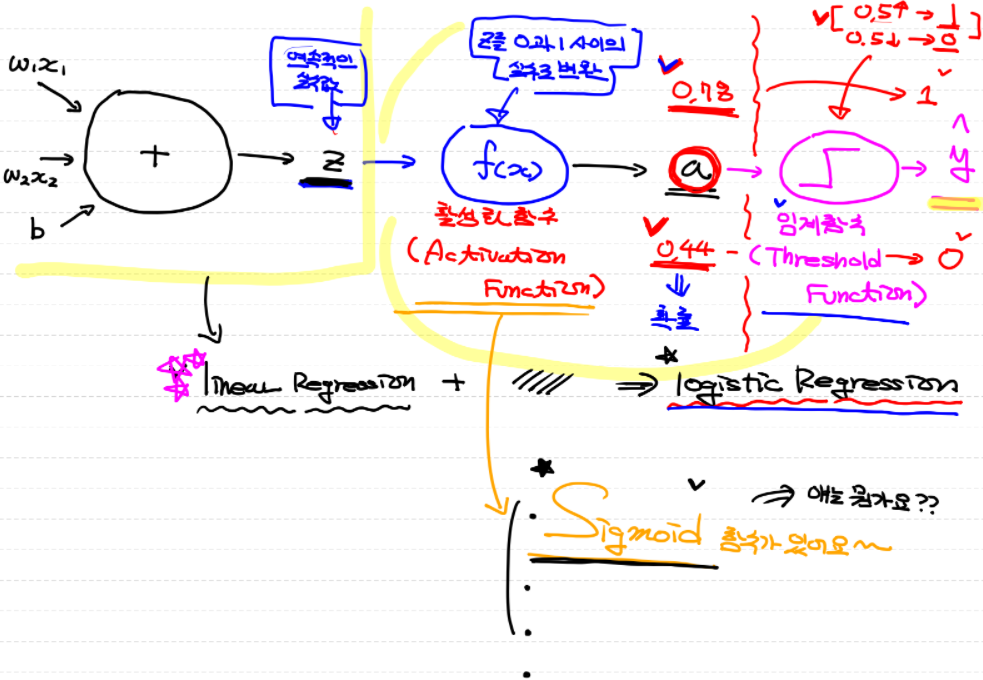
여기까지가 Linear Regression!
이제부터 Classification!
Linear Regression을 확장해서 Classification(분류)가 가능한 모델로 만듦
- Binary Classification(이항분류) : 주식을 사야 하나 말아야 하나, 닭인가 백조인가
- Multinomial Classification(다항분류) : 학점, 등급

이항분류부터 살펴보고 Logistic Regression으로 넘어감! → Deep Learning의 기본 component
Logistic은 perception으로부터 기인함
| 1. 3/15 화 | 2. 3/16 수 | 3. 3/17 목 | 4. 3/18 금 | 5. 3/21 월 |
| ML 환경 설정 (아나콘다, 주피터 노트북), Pandas, Numpy, ndarray |
ML Numpy, 행렬곱연산, 전치행렬, iterator, axis, Pandas, Series, DataFrame |
ML Pandas, DataFrame, 함수들 |
ML Pandas, 데이터 분석, 데이터 전처리 |
ML Pandas, 데이터 전처리, 수행평가 |
| 6. 3/22 화 | 7. 3/23 수 | 8. 3/24 목 | 9. 3/25 금 | 10. 3/28 월 |
| ML 데이터 시각화, Matplotlib, 기술통계 |
ML 기술통계 |
ML 기술통계, 머신러닝 |
ML 미분, Regression |
ML 머신러닝 기법들, Regression |
| 11. 3/29 화 | 12. 3/30 수 | 13. 3/31 목 | 14. 4/1 금 | 15. 4/4 월 |
| ML Regression 구현 (Python, Scikit-Learn) |
ML Outlier, Z-score, MinMaxScaler, 다변수 |
ML Tensorflow, Classification |
ML Classification, Logistic Regression |
* Regression에 대한 기본이 탄탄해야 다음으로 넘어갈 수 있다!



