화요일!
데이터를 시각화하는 대표적인 라이브러리인 Matplotlib에 대해 배운다!
Matplotlib 안에 Pyplot이라는 sub package를 사용한다.
Line plot(선 그래프), Histogram(도수표), Scatter(산점도), Box plot,
그 외 Area plot, Bar chart(막대 그래프)
1. Line plot(선 그래프) : 연속적인 값의 경향을 파악할 때 주로 사용(시계열)
import pandas as pd
import matplotlib.pyplot as plt
# 1. Line plot(선 그래프)
plt.title('Line Plot') # plot의 제목을 설정
plt.plot([1, 5, 12, 25]) # x축의 자료 위치(x 축 눈금) -> tick은 기본적으로 0, 1, 2, 3
plt.show() # 화면에 plot을 rendering 하고 마우스 이벤트를 기다리는 함수
# 만약 코드를 pycharm과 같은 일반 개발 툴을 이용하면 이 명령어를 이용해야 그래프가 나옮. Jupyter Notebook은 굳이 쓸 필요 없음
plt.plot([10, 20, 30, 40], [1, 5, 12, 25]) # x축 y축
Anaconda Prompt 열어서 가상 환경에 openpyxl 모듈 설치
conda activate machine
conda install openpyxl통계청의 전입/전출 데이터를 사용해 Line plot을 만들어보자
df = pd.read_excel('./data/lineplot_sample_data.xlsx')
# display(df.head())
df = df.fillna(method='ffill') # 전출지별의 NaN 값을 이전 행의 값으로 대체
# display(df.head(25))
# 서울특별시에서 다른 지역으로 전입한 데이터만 가져오자
bool_mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df.loc[bool_mask, :]
# display(df_seoul)
df_seoul.drop('전출지별', axis=1, inplace=True)
df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True) # DataFrame의 column 명을 변경
df_seoul.set_index('전입지', inplace=True) # index를 전입지로 바꿈
display(df_seoul.head(3))
s = df_seoul.loc['경기도'] # 서울에서 경기도로 전입한 데이터만 연도별로 가져오자
# print(s)
# plt.title('seoul -> gyeonggi')
# plt.title('서울에서 경기도로 전입한 사람 추이') # Matplotlib은 한글 지원 안 함. font가 필요함!
import matplotlib as mpl # font 잡는데 필요한 모듈 불러오기
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from matplotlib import rc
font_path = './font/malgun.ttf' # ttf 파일을 jupyter notebook 디렉터리 안에 넣기
font_name = fm.FontProperties(fname=font_path).get_name() # fm으로 font 이름 알아오기
# print(font_name) # Malgun Gothic
rc('font', family=font_name) # family는 font를 지칭함
plt.title('서울에서 경기도로 전입한 사람 추이')
import warnings # 원본 DataFrame을 변경하는 것에 대한 경고문 안 나오게
warnings.filterwarnings(action='ignore')
mpl.rcParams['axes.unicode_minus'] = False # 그래프에서 '-' 기호 때문에 발생하는 문제 방지하기 위한 설정
plt.xlabel('연도')
plt.ylabel('이동 인구수')
plt.plot(s.index, s.values) # Line plot의 x축 y축을 인덱스와 컬럼 값으로 지정
plt.show()
그래프에 스타일을 적용해보자
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from matplotlib import rc
import warnings
warnings.filterwarnings(action='ignore')
mpl.rcParams['axes.unicode_minus'] = False
font_path = './font/malgun.ttf'
font_name = fm.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
plt.style.use('ggplot') # 그래프에 스타일(ggplot)을 적용
plt.figure(figsize=(10, 5)) # 그래프의 크기를 설정. figsize 옵션으로 가로/세로 길이(inch)를 지정
plt.xticks(rotation='vertical') # x의 눈금을 읽기 어렵기 때문에 label을 회전시킴
plt.plot(s.index, s.values,
marker='o', markersize=8, markerfacecolor='r', # marker를 circle로 지정, s는 square. size는 크기, facecolor는 색
color='g', linewidth=2) # color는 선의 색, linewidth는 선 굵기
plt.title('서울에서 경기도로 전입한 사람 추이')
plt.xlabel('연도')
plt.ylabel('이동 인구수')
plt.legend(labels=['서울 -> 경기'], loc='best') # 범례. loc는 위치 알아서
plt.show()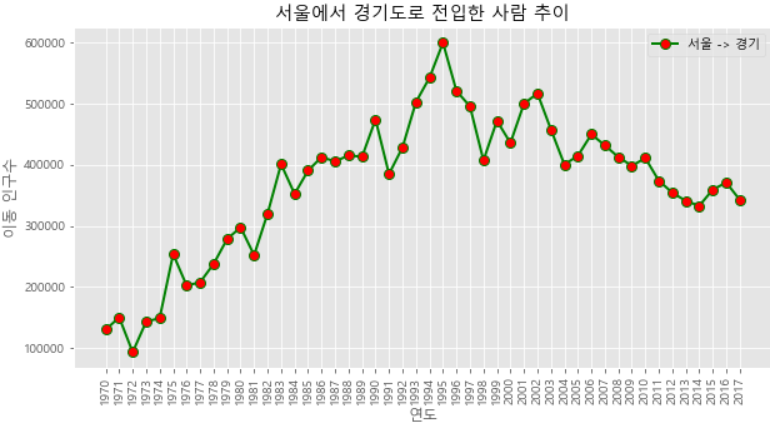
그래프 여러 개를 한 번에 그리는 방법인 sub-plot. figure, axes, axis
figure는 canvas(도화지)를 나타내는 객체. plot()을 사용하면 자동으로 figure 만듦. plt.figure()로 크기 설정 가능
figure 객체는 1개 이상의 axes로 구성됨. plot()이 자동으로 1개 만듦. sub-plot으로 여러 개 만들 수 있음
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import matplotlib.font_manager as fm
from matplotlib import rc
import warnings
warnings.filterwarnings(action='ignore')
mpl.rcParams['axes.unicode_minus'] = False
font_path = './font/malgun.ttf'
font_name = fm.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
plt.style.use('ggplot')
df = pd.read_excel('./data/lineplot_sample_data.xlsx')
df = df.fillna(method='ffill')
bool_mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
df_seoul = df.loc[bool_mask, :]
df_seoul.drop('전출지별', axis=1, inplace=True)
df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True)
df_seoul.set_index('전입지', inplace=True)
s = df_seoul.loc['경기도']
fig = plt.figure(figsize=(10,10))
ax1 = fig.add_subplot(1,2,1) # .add_subplot(행, 열, axes). axes 추가. 1행 2열의 첫번째 axes
ax2 = fig.add_subplot(1,2,2) # 1행 2열의 두번째 axes
ax1.set_title('서울 -> 경기 인구 이동')
ax1.set_xlabel('연도')
ax1.set_ylabel('이동 인구수')
ax1.plot(s.index, s.values)
ax2.plot(s.index, s.values, marker='o', markersize=8, markerfacecolor='r', color='g', linewidth=2)
plt.show()
2. Histogram(도수표) : 단변수(변수가 하나) 데이터의 빈도수를 그래프로 표현한 것
x축을 같은 크기의 여러 구간(bin)으로 나누고, y축은 해당 구간 안에 포함된 데이터의 개수(빈도, mode)를 표현
당연히 x축의 구간을 조절하면 도수표의 모양이 달라짐
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
df = pd.read_csv('./data/auto-mpg.csv', header=None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'year', 'origin', 'name']
display(df.head(3))
print(df['mpg'].max(), df['mpg'].min())
# mpl이 아닌 Pandas의 기능을 이용해서 도수표를 그려보자
df['mpg'].plot(kind='hist', bins=10, color='blue', figsize=(10,5)) # kind=차트의 종류. bins=구간
plt.show()
3. Scatter(산점도) : 서로 다른 두 변수 사이의 관계를 표현
두 변수의 값을 각각 x와 y축에 하나씩 놓고 데이터 값이 위치하는 좌표(x, y)를 찾아서 점을 찍음
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
df = pd.read_csv('./data/auto-mpg.csv', header=None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'year', 'origin', 'name']
display(df.head(3))
df.plot(kind='scatter', x= 'weight', y= 'mpg', # kind=산점도, x축, y축
color='r', s=10, figsize=(10,5)) # 점의 색, 점의 크기
plt.show()
4. Box plot : 4분위 값을 이용. 데이터의 분포를 확인할 수 있음. outlier(이상치)가 그래프에 표현됨
1분위 값은 전체 범위에서 25%, 2분위(중위) 값은 50%, 3분위 값은 75%
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('./data/auto-mpg.csv', header=None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'year', 'origin', 'name']
plt.boxplot(x=[df.loc[df['origin'] == 1, 'mpg'],
df.loc[df['origin'] == 2, 'mpg'],
df.loc[df['origin'] == 3, 'mpg']])
plt.show()
데이터의 시각화가 끝나고 기술통계로 넘어간다!
데이터의 종류 : 수치(키 185cm), 범주형(카테고리. 설문조사. 만족/불만족)
데이터의 분류
- 질적 변수(Qualitative Variable) : 선택이 필요한 변수(설문), 종류를 구분하기 위한 변수(혈액형)
- 양적 변수(Quantitative Variable) : 시험 점수, 신장, 체중
* 숫자라고 해서 무조건 양적 변수인 것은 아님!
질적 변수는
- 명목 변수와 : 단순히 분류를 목적으로 함. 연산과 대소 관계는 의미가 없음. ex) 학번, 전화번호
- 순위 변수로 나뉨 : 순위나 대소 관계에 의미가 있는 변수. ex) 성적순위, 설문조사의 만족도
양적 변수는
- 간격 변수와 : 대소 관계와 그 차이에도 의미를 두는 변수 ex) 연도(1990년, 1995년. 5년 차이)
- 비율 변수로 나뉨 : 대소, 차이, 비례에 의미를 두는 변수 ex) kg(무게), cm(길이)
확률 변수는
- 이산형 변수와 : 인접한 숫자 사이에 다른 값이 존재하지 않는 변수 ex) 정수, 주사위의 눈
- 연속형 변수로 나뉨 : 인접한 숫자 사이에 다른 값이 존재하는 변수 ex) 실수, 신장, 몸무게
* 소수점 1 자리까지만 표현한다는 가정이 있으면 이산형 변수!
1차원 데이터의 특징 파악
- 수치지표 → 평균, 편차, 분산, 표준편차...
- 시작적 표현 → Histogram
2차원 데이터의 특징 파악
- 수치지표 → 공분산, 상관계수
- 시작적 표현 → scatter
| 1. 3/15 화 | 2. 3/16 수 | 3. 3/17 목 | 4. 3/18 금 | 5. 3/21 월 |
| ML 환경 설정 (아나콘다, 주피터 노트북), Pandas, Numpy, ndarray |
ML Numpy, 행렬곱연산, 전치행렬, iterator, axis, Pandas, Series, DataFrame |
ML Pandas, DataFrame, 함수들 |
ML Pandas, 데이터 분석, 데이터 전처리 |
ML Pandas, 데이터 전처리, 수행평가 |
| 6. 3/22 화 | 7. 3/23 수 | 8. 3/24 목 | 9. 3/25 금 | 10. 3/28 월 |
| ML 데이터 시각화, Matplotlib, 기술통계 |
ML 기술통계 |
ML |
ML |
ML |
* 공부할게 쌓이지 않도록 그날그날 충분히 복습/실습하자!



