목요일!
기술통계를 이어서 배운다.
기술통계가 끝나면 추리통계(통계분석. 추측. 전수조사, 모집단)가 수순이지만 멀캠에서 배우지는 않는다!
1차원 데이터의 특징 파악
- 수치지표 → 대표값 : 평균, 중위값, 최대/최소값, 편차, 분산, 표준편차...
- 시작적 표현 → 도수분포표, Histogram, Box plot
2차원 데이터의 특징 파악
- 수치지표 → 공분산, 상관계수
- 시작적 표현 → Scatter
2차원 데이터의 수치지표 → 공분산, 상관계수
1. 공분산(covariance) : 두 확률변수 사이의 상관 정도
import numpy as np
import pandas as pd
df = pd.read_csv('./data/student_scores_em.csv',
index_col='student number')
en_scores = df['english'][:10]
ma_scores = df['mathematics'][:10]
scores_df = pd.DataFrame({'english': en_scores.values,
'mathematics': ma_scores.values},
index=['A','B','C','D','E','F','G','H','I','J'])
scores_df['en_deviation'] = scores_df['english'] - scores_df['english'].mean()
scores_df['ma_deviation'] = scores_df['mathematics'] - scores_df['mathematics'].mean()
scores_df['product_deviation'] = scores_df['en_deviation'] * scores_df['ma_deviation']
display(scores_df)
print('covariance(공분산) : ', scores_df['product_deviation'].mean()) # 62.8. 양의 상관관계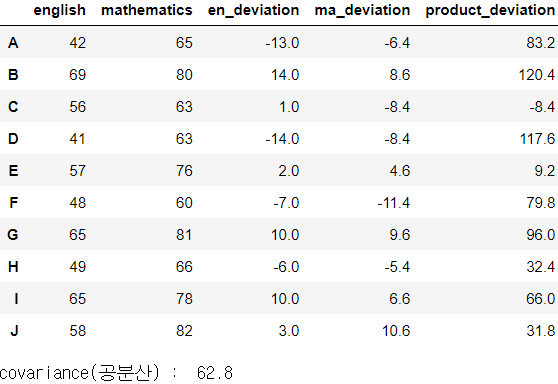

# Numpy의 함수를 이용해 공분산 구하기. 결과가 covariance matrix(공분산 행렬)로 리턴
# 편차의 곱의 평균(공분산)을 구하는데 평균을 구할 때 n으로 나누는 경우와 n-1로 나누는 경우가 있음
cov_matrix = np.cov(en_scores, ma_scores, ddof=0) # 평균을 구할 때 n으로 나누는 표본분산
print(cov_matrix)
# 0행 0열 - 영어와 영어의 공분산 -> 영어의 분산
# 0행 1열 - 영어와 수학의 공분산
# 1행 0열 - 수학과 영어의 공분산
# 1행 1열 - 수학과 수학의 공분산 -> 수학의 분산
# Pandas에도 cov() 존재하지만, 무조건 n-1로 나누는 불편분산 형태로 사용됨
# [[86. 62.8 ]
# [62.8 68.44]]
2. 실제 데이터를 이용해서 공분산을 구해보자. KOSPI 지수 vs. 삼성전자 주가 / 남북경협주 vs. 방산주 주가
Yahoo Finance에서 KOSPI 지수, 삼성전자 주가를 가져오기 위해,
Anaconda Prompt에서 pandas_datareader 모듈 설치
conda activate machine
pip install pandas_datareaderimport numpy as np
import pandas as pd
import pandas_datareader.data as pdr
from datetime import datetime
start = datetime(2018,1,1) # 2018-01-01 00:00:00
end = datetime(2018,12,31) # 2018-12-31 00:00:00
df_kospi = pdr.DataReader('^KS11', 'yahoo', start, end) # Yahoo Finance에서 KOSPI 지수, 삼성전자 주가를 가져오기. 주가 코드
# display(df_kospi) # 고점, 저점, 시가, 종가, 거래량, 수정종가
df_se = pdr.DataReader('005930.KS', 'yahoo', start, end)
# display(df_se)
cov_matrix = np.cov(df_kospi['Close'], df_se['Close'], ddof=0)
print(cov_matrix) # 488212.99831291. KOSPI 지수와 삼성전자 주가는 양의 상관관계
# 음의 상관관계인 데이터를 보자! 남북경협주, 방산주
df_pusan = pdr.DataReader('011390.KS', 'yahoo', start, end) # 남북경협주, 부산산업
df_lig = pdr.DataReader('079550.KS', 'yahoo', start, end) # 방산주, LIG넥스원
cov_matrix = np.cov(df_pusan['Close'], df_lig['Close'], ddof=0)
print(cov_matrix) # -3.84951773e+08. 남북경협주와 방산주 주가는 음의 상관관계
3. 변수 두 개가 서로 다른 단위일 경우 공분산 값이 달라짐 ex) 키(m, cm, mm) vs. 점수(숫자)
→ normalization로 단위, 숫자 크기를 표준화함. 상관계수(correlation coefficient)
계산 결과가 -1~1 사이. 0은 서로 연관성이 없음. 대표적인 것이 피어슨 상관계수
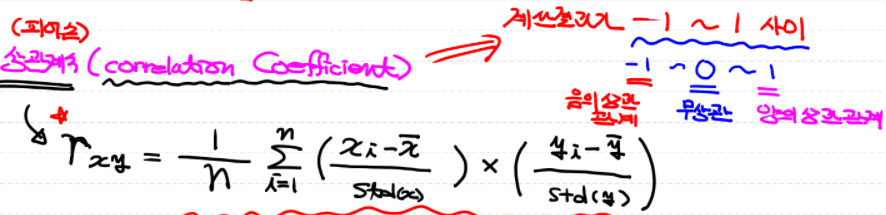
하지만, 일반적으로 상관관계가 인과관계를 설명하지는 않음 ex) 성적과 자존감, 게임과 폭력성
→ 인과관계는 회귀분석(regression analysis)을 사용
df_kospi = pdr.DataReader('^KS11', 'yahoo', start, end)
df_se = pdr.DataReader('005930.KS', 'yahoo', start, end)
corr_coef = np.corrcoef(df_kospi['Close'], df_se['Close'])
print(corr_coef) # 0.91317306. KOSPI 지수와 삼성전자 주가의 상관계수
여기까지 기술통계 끝!
이제 머신러닝 시작! 데이터 수집(크롤링 등)은 배우지 않는다~
AI(Artificial Intelligence) : 인공지능. 사람의 사고능력을 구현한 프로그램(시스템). 데이터로 Weak AI를 만들기 위한 방법론!
사람 - 생화학적 방식으로 사고
Strong AI - 사람과 구별할 수 없는 정도의 강한 AI. 전자기적 방식으로 사고 ex) 매트릭스 오라클, 아키텍트, Deus Ex Machina
Weak AI - 특정 영역에서 잘 동작하는 AI. ex) 자율주행, 챗봇, 검색
- 기존 프로그램 방식(Rule Based Programming) : computer vision이 사람과 다르게 어려움. 수많은 조건에 따라 동작함
- Machine Learning : 사진 data가 무엇인지 알려주고 학습을 시켜 규칙성(모델, 수식)을 점차 부여함 → 지도 학습
데이터를 기반으로 특성과 패턴을 파악한 후 그 결과(model)를 이용해 미지의 데이터에 대한 추정치 계산하는 프로그램
양질의 데이터가 많아야!
< 기법(방식) >
- Regression(회귀)
- SVM(Support Vector Machine)
- Decision Tree, Random Forest
- Naive Bayes
- KNN(K-Nearest Neighbor)
- Neural Network(신경망) : 딥러닝! 알고리즘(CNN, RNN(LSTM), DNN, GNN)
- Clustering(K-Means, DBScan)
- Reinfacement Learning(강화 학습)
딥러닝을 제외한 머신러닝 알고리즘은 정형 데이터 처리에 조금 더 적합함, 시간이 덜 소요됨
딥러닝은 비정형 데이터(이미지, 소리, 대용량 text, 언어) 처리에 적합함, 시간이 더 걸림
기존 프로그램 방식(Rule Based Programming)과 달리 동작 조건들을 다 구현하지 못하는 경우 머신러닝이 필요함
< 머신러닝의 타입(분류) >
- 지도 학습(Supervised Learning) : Training Data Set(학습 데이터)
입력되는 것들은 data(입력값, x), data의 label(해답, 정답, t)
두 가지 종류의 미래 값을 예측함 → Regression(회귀. 예측값이 연속적인 수치값으로 나오는 경우), Classification(분류. 예측값이 어느 분류에 속하는가로 나오는 경우)
- 비지도 학습(Unsupervised Learning) : 입력에 data의 label이 들어가지 않음. Clustering(군집화. data의 특징이 유사한 것끼리 모음)
- 준지도 학습(Semisupervised Learning) : 지도 + 비지도. 입력에 data의 label이 다는 들어가지 않음. ex) google photos
- 강화 학습(Reinforcement Learning) : Action, Reward 개념을 이용해 최상의 policy(정책)을 찾음
< 머신러닝 Process >
1. 문제 파악 : Domain 분석
2. EDA(탐색적 데이터 분석) : 데이터 수집, 내부 데이터 및 외부 데이터 활용 여부, 결측치 · 이상치 확인, 분포 확인, 변수 간의 상관관계
3. 데이터의 Pre-Processing
4. 모델 학습 : 순수 Python으로 구현, Tensorflow로 구현, Scikit-learn
5. Prediction
| 1. 3/15 화 | 2. 3/16 수 | 3. 3/17 목 | 4. 3/18 금 | 5. 3/21 월 |
| ML 환경 설정 (아나콘다, 주피터 노트북), Pandas, Numpy, ndarray |
ML Numpy, 행렬곱연산, 전치행렬, iterator, axis, Pandas, Series, DataFrame |
ML Pandas, DataFrame, 함수들 |
ML Pandas, 데이터 분석, 데이터 전처리 |
ML Pandas, 데이터 전처리, 수행평가 |
| 6. 3/22 화 | 7. 3/23 수 | 8. 3/24 목 | 9. 3/25 금 | 10. 3/28 월 |
| ML 데이터 시각화, Matplotlib, 기술통계 |
ML 기술통계 |
ML 기술통계, 머신러닝 |
ML 수학 |
ML |
* 전반적인 내용을 파악하자!



